Le tracking server-side s’impose aujourd’hui comme une alternative solide au tracking client-side pour la collecte et l’analyse de données. En déplaçant la gestion des balises vers le serveur, cette méthode assure une plus grande précision des données, une meilleure protection de la vie privée des utilisateurs et une performance web accrue. Dans cet article, nous explorerons en détail ce qu’est le tracking server-side, ses avantages et comment l’implémenter dans une stratégie de data tracking.
Qu’est-ce que le tracking Server-Side ?
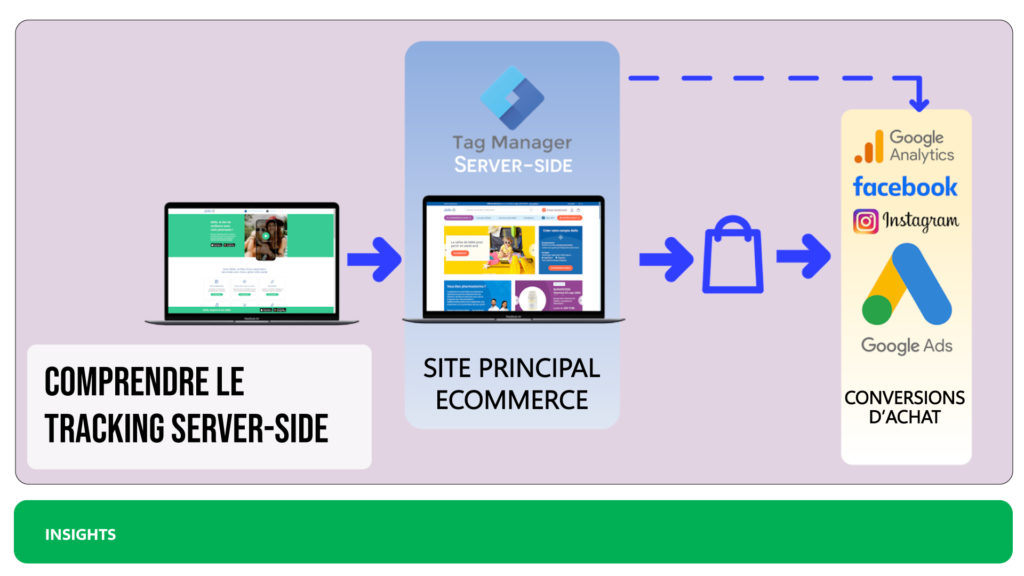
Contrairement au tracking client-side, où le suivi des utilisateurs est géré directement sur le navigateur via des balises JavaScript, le tracking server-side centralise la collecte des données en les traitant directement sur un serveur distant. Les informations des visiteurs sont envoyées vers un serveur de tracking spécifique qui analyse les données et les redirige vers les plateformes de marketing ou d’analyse, comme Google Ads, Facebook Ads ou Google Analytics 4, etc.
En bref, au lieu de faire passer les informations de l’utilisateur depuis son navigateur vers les différents outils de suivi, les données transitent d’abord par un serveur central. Ce système permet d’assurer un contrôle plus fin et une meilleure confidentialité des données.
Source : https://developers.google.com/tag-platform/tag-manager/server-side/intro?hl=fr
Pourquoi choisir un tracking Server-Side ?
Dans un paysage numérique en constante évolution, où la protection des données est devenue une priorité absolue, le tracking server-side s’impose comme la solution idéale pour les entreprises soucieuses de maîtriser leur data et d’optimiser leurs performances marketing. Voici les principaux avantages :

- Amélioration de la précision des données : Contrairement au tracking client-side, sensible aux ad-blockers et aux restrictions de navigateur, le tracking server-side offre des données plus fiables et complètes.
- Blocage des cookies tiers : Les navigateurs comme Safari et Firefox bloquent par défaut les cookies tiers, et Google prévoit de suivre la même voie. Le tracking server-side permet de contourner cette restriction en transférant les données via des serveurs sécurisés.

- Meilleur contrôle de la confidentialité et conformité réglementaire : La LPD en Suisse, la RGPD en Europe et le CCPA en Californie imposent des règles strictes sur la collecte et le traitement des données personnelles. Ce modèle limite l’usage des cookies sur le navigateur de l’utilisateur.
- Optimisation des performances : Le traitement des données côté serveur allège le chargement des pages et améliore l’expérience utilisateur en réduisant les requêtes exécutées directement sur le navigateur. Les sites se chargent plus rapidement, ce qui réduit le taux de rebond et améliore le SEO.
Comment mettre en place le tracking Server-Side ?
Mettre en place un tracking côté serveur requiert quelques étapes techniques. Voici un aperçu des principales étapes :
- Choisir une Tag Management System (TMS) : Parmi les plus populaires, on retrouve Google Tag Manager (GTM) Server-Side mais il existe d’autres plateformes comme Segment et Tealium.
- Configurer le serveur pour la réception des données. Il est possible d’utiliser des solutions de cloud comme Google Cloud Platform, AWS, ou Microsoft Azure pour héberger le serveur de collecte.
- Intégrer les balises des plateformes de marketing (Meta, TikTok, LinkedIn, DV360, Google Ads, etc.) et d’analyse et rediriger les balises existantes de client-side à server-side.
- Collecter les événements et transmettre les données : Le tracking côté serveur fonctionne en interceptant les requêtes des utilisateurs sur le serveur du site web avant de les envoyer aux plateformes. Par exemple, lorsqu’un utilisateur effectue une action sur un site web (clic, scroll, etc.), cette action est d’abord enregistrée par le serveur, qui ensuite relaie l’information à la plateforme. Ce modèle garantit que les données sont filtrées et nettoyées avant d’être transmises, réduisant ainsi le risque d’erreurs ou de duplication.
- Tester pour s’assurer que les données sont bien transmises et exploitables. Avant de lancer le tracking en production, il est essentiel de tester la configuration sur différents navigateurs et appareils pour s’assurer que les données sont collectées de manière fiable et conforme.
- Suivi et optimisation : Une fois en place, le tracking server-side doit être suivi et optimisé en continu. Il est recommandé de surveiller les performances des serveurs et de mettre à jour les règles de collecte pour s’adapter aux évolutions réglementaires et technologiques.
Quels sont les défis du tracking Server-Side ?
Bien que prometteur, le tracking server-side présente quelques défis :
- Complexité de la mise en œuvre
La configuration d’un tracking server-side nécessite des compétences techniques poussées et une infrastructure serveur performante. - Coût
Contrairement au tracking client-side, le server-side implique des coûts supplémentaires en termes d’hébergement. Le choix d’un modèle adapté à son budget et à ses objectifs est donc essentiel. - Impact sur la collecte des consentements
Les plateformes server-side doivent être configurées pour respecter les préférences de consentement des utilisateurs, ce qui peut complexifier la gestion du CMP (Consent Management Platform). Les entreprises doivent s’assurer que la configuration server-side respecte bien les choix des utilisateurs en matière de consentement.
Mise en perspective avec les enjeux actuels
Le « cookieless future » et le tracking server-side pour les annonceurs
L’évolution vers un avenir sans cookies tiers, accélérée par des réglementations renforcées en matière de protection de la vie privée et les initiatives des navigateurs pour limiter leur utilisation, transforme profondément le marketing digital. Cette transition réduit les capacités traditionnelles de suivi et de ciblage, impactant directement les annonceurs.
Dans ce contexte, le tracking côté serveur (server-side tracking) émerge comme une solution pertinente pour les annonceurs. En déplaçant la logique de suivi vers le serveur, cette méthode contourne les restrictions liées aux cookies tiers, assurant une continuité dans la collecte et l’analyse des données. Les indicateurs clés de performance (KPI) tels que le taux de conversion, le coût par acquisition (CPA) et le retour sur investissement (ROI) gagnent en stabilité, car les données collectées via le serveur sont moins sujettes aux pertes causées par les bloqueurs de publicités ou les politiques de confidentialité. Ainsi, les annonceurs peuvent maintenir un niveau de personnalisation et d’efficacité dans leurs campagnes marketing, tout en respectant les nouvelles exigences en matière de confidentialité.
Intégration du tracking server-side et du Privacy Sandbox : la clé pour déverrouiller un avenir publicitaire plus respectueux de la vie privée
Le Privacy Sandbox de Google est un ensemble d’API et de technologies conçues pour permettre aux éditeurs de site web de continuer à proposer des expériences publicitaires personnalisées, tout en respectant la vie privée des utilisateurs. Le tracking server-side s’aligne parfaitement avec cette initiative en proposant une alternative aux cookies tiers qui est compatible avec les nouvelles normes de Google.
Dans le cadre du Privacy Sandbox, le tracking côté serveur peut être utilisé pour implémenter des solutions telles que la Topics API. Cette dernière attribue à chaque utilisateur des thèmes d’intérêt, basés sur son historique de navigation récent, mais sans divulguer d’informations personnelles identifiables. Ces thèmes, calculés localement sur l’appareil de l’utilisateur, sont ensuite partagés avec les annonceurs pour proposer des publicités pertinentes.
En complément de la Topics API, des solutions comme Protected Audience API et Attribution Reporting offrent des fonctionnalités avancées pour mesurer l’efficacité des campagnes publicitaires et attribuer les conversions. Protected Audience API permet de sélectionner et de diffuser des annonces de manière plus privée, tandis qu’Attribution Reporting fournit des données plus précises sur le parcours client.
En combinant tracking server-side et Privacy Sandbox, les entreprises peuvent ainsi continuer à proposer des expériences publicitaires ciblées, tout en respectant le choix des utilisateurs et en se conformant aux nouvelles réglementations en matière de protection des données.
Source : https://developers.google.com/privacy-sandbox/private-advertising/topics?hl=fr
En conclusion, quel avenir pour le tracking Server-Side ?
Le tracking server-side représente une avancée majeure pour les entreprises cherchant à optimiser leur collecte de données tout en respectant les contraintes de performance et de confidentialité. À mesure que les navigateurs renforcent leurs restrictions sur les cookies tiers et que les consommateurs deviennent plus sensibles à la protection de leurs données, le tracking server-side pourrait bien s’imposer comme LA norme pour toute stratégie data ambitieuse et durable. Les entreprises qui adopteront cette approche gagneront un avantage concurrentiel en offrant une expérience respectueuse de la vie privée à leurs utilisateurs.
Pour une transition réussie, il est recommandé de collaborer avec des experts en tracking et en gestion de la conformité, comme les spécialistes GTM et RGPD/LPD chez Mediamix, afin de garantir un déploiement optimal. Contactez-nous pour bénéficier de notre expertise.
FAQ sur le tracking Server-Side
Le Tracking Server-Side est-il adapté à toutes les entreprises ?
Le tracking server-side peut être bénéfique pour les entreprises de toutes tailles, mais il est surtout recommandé pour celles qui ont des besoins avancés en matière de suivi de données (site ecommerce). En revanche, pour les entreprises de petite taille ou ayant un budget limité, les solutions client-side peuvent être suffisantes, à condition de respecter les bonnes pratiques de confidentialité et de sécurité des données.
Quels sont les coûts associés au tracking server-side ?
La mise en place d’une infrastructure server-side peut être coûteuse, mais le retour sur investissement est souvent substantiel pour les entreprises axées sur les données.
Si vous optez pour des plateformes comme Google Tag Manager Server-Side, certaines fonctions peuvent être gratuites, mais d’autres (comme l’hébergement) seront facturées en fonction de l’utilisation.
Peut-on continuer à utiliser un TMS client-side en parallèle du tracking server-side ?
Il est tout à fait possible d’utiliser les deux en parallèle pendant une période de transition. Cela permet de comparer les résultats et de s’assurer que la migration vers le server-side se déroule correctement. Cependant, à long terme, il est recommandé de privilégier une approche server-side pour bénéficier de tous les avantages de cette technologie.
Qu’est-ce que FLoC (Federated Learning of Cohorts) ?
FLoC est une technologie développée par Google pour proposer des publicités ciblées sans recourir aux cookies tiers. Elle regroupe les utilisateurs en « cohortes » (groupes) selon leurs intérêts, ce qui permet de cibler des audiences sans identifier les individus. Chaque utilisateur est ainsi inclus dans une cohorte de milliers d’autres personnes ayant des comportements similaires en ligne. En 2021, Google a cessé le développement de FLoC en raison de préoccupations liées à la confidentialité et à l’efficacité. Cette technologie a été remplacée par l’API Topics, qui attribue aux utilisateurs des thèmes d’intérêt basés sur leur historique de navigation récent, sans divulguer d’informations personnelles identifiables.
Source : https://privacysandbox.com/intl/en_us/proposals/floc/
Qu’est-ce que Topics API ?
Cette API fait partie de la Privacy Sandbox de Google et remplace le FLoC. Elle associe chaque utilisateur à une série de sujets d’intérêt général (par exemple, « technologie » ou « voyages ») en fonction de sa navigation récente. Ces sujets sont ensuite partagés avec les plateformes publicitaires pour proposer des publicités pertinentes sans transmettre de données personnelles spécifiques.
Source : privacysandbox.com
Qu’est-ce que Protected Audience API ?
La Protected Audience API, anciennement connue sous le nom de FLEDGE, est une proposition de Google dans le cadre de l’initiative Privacy Sandbox. Elle vise à permettre le reciblage publicitaire et la création d’audiences personnalisées sans recourir aux cookies tiers, tout en préservant la confidentialité des utilisateurs.
Fonctionnement de la Protected Audience API :
- Groupes d’intérêt : Lorsqu’un utilisateur visite un site web, ce dernier peut demander au navigateur de l’ajouter à un groupe d’intérêt spécifique, basé sur les interactions de l’utilisateur avec le site. Ces informations sont stockées localement dans le navigateur.
- Enchères locales : Lorsqu’un utilisateur visite un site disposant d’espaces publicitaires, le navigateur exécute une enchère locale en utilisant les données des groupes d’intérêt auxquels l’utilisateur appartient. Cette enchère détermine quelle publicité afficher, sans que les données de l’utilisateur ne soient partagées avec des tiers.
- Affichage des annonces : La publicité sélectionnée est affichée à l’utilisateur via un cadre sécurisé, garantissant que les données de l’utilisateur ne sont pas exposées.
Source : https://developers.google.com/privacy-sandbox/private-advertising/protected-audience?hl=fr
Que-est-ce que l’Attribution Reporting API ?
L’Attribution Reporting API est une initiative de Google dans le cadre du projet Privacy Sandbox, visant à mesurer l’efficacité des publicités en ligne tout en préservant la confidentialité des utilisateurs. Cette API permet aux annonceurs et aux plateformes publicitaires de déterminer si une interaction avec une annonce (comme un clic ou une impression) conduit à une conversion, telle qu’un achat ou une inscription, sans recourir aux cookies tiers.
Source : https://developers.google.com/privacy-sandbox/private-advertising/attribution-reporting
Fonctionnement de l’Attribution Reporting API :
- Enregistrement des sources : Lorsqu’un utilisateur interagit avec une annonce sur un site éditeur, cette interaction est enregistrée comme une « source d’attribution ».
- Enregistrement des déclencheurs : Si l’utilisateur effectue ultérieurement une action de conversion sur le site de l’annonceur, cette action est enregistrée comme un « déclencheur d’attribution ».
- Rapports d’attribution : L’API associe les sources et les déclencheurs pour générer des rapports indiquant l’efficacité des campagnes publicitaires, tout en limitant les informations partagées afin de protéger la vie privée des utilisateurs.










